RESEARCH
Advancing Autonomous Construction and Comprehension of Real Estate Financial Models
Introduction
XL-2: A purpose-built tooling layer that mediates between a foundation model backbone and the structured financial modeling environment.
Today we are releasing a paper on XL-2, an agentic system that autonomously builds and interprets institutional-grade commercial real estate financial models.
The full technical paper is available here.
Real Estate Financial Models Are Computational Systems
A commercial real estate acquisition model is not a spreadsheet in the way that most AI research uses the term. A single institutional deal model may comprise 20 to 40 interconnected worksheets, tracking 500+ lease terms across 80+ tenants, layering senior debt, mezzanine financing, and preferred equity with distinct payment priorities, computing levered and unlevered returns at both the asset and partnership level, and running sensitivity across a combinatorial space of rent growth, cap rate, and financing assumptions. Change one input — a 50-basis-point shift in exit cap rate — and the effect propagates through cash flow projections, debt coverage ratios, waterfall distributions, and return metrics simultaneously.
These models are where capital allocation decisions get made. A structural error in a promote waterfall is not a rounding issue. It is a misallocation of investor capital.
Where Current LLMs Fall Short
State-of-the-art language models can compute IRRs, build discounted cash flow tables, and structure waterfall logic when given clean, well-specified inputs. We've found that the failure point is upstream of reasoning.
Present a 30-tab acquisition model to a frontier LLM and it cannot reliably determine which cells contain assumptions versus computed outputs. It cannot trace how a cash flow line on tab 12 connects back through a lease schedule on tab 4 that references an escalation table on tab 2. It cannot distinguish two cells both labeled "Cap Rate" that mean different things depending on their position in the workbook — one is an exit assumption, the other is a derived terminal value.
The model can do the math. It cannot find its way around the spreadsheet.
XL-2
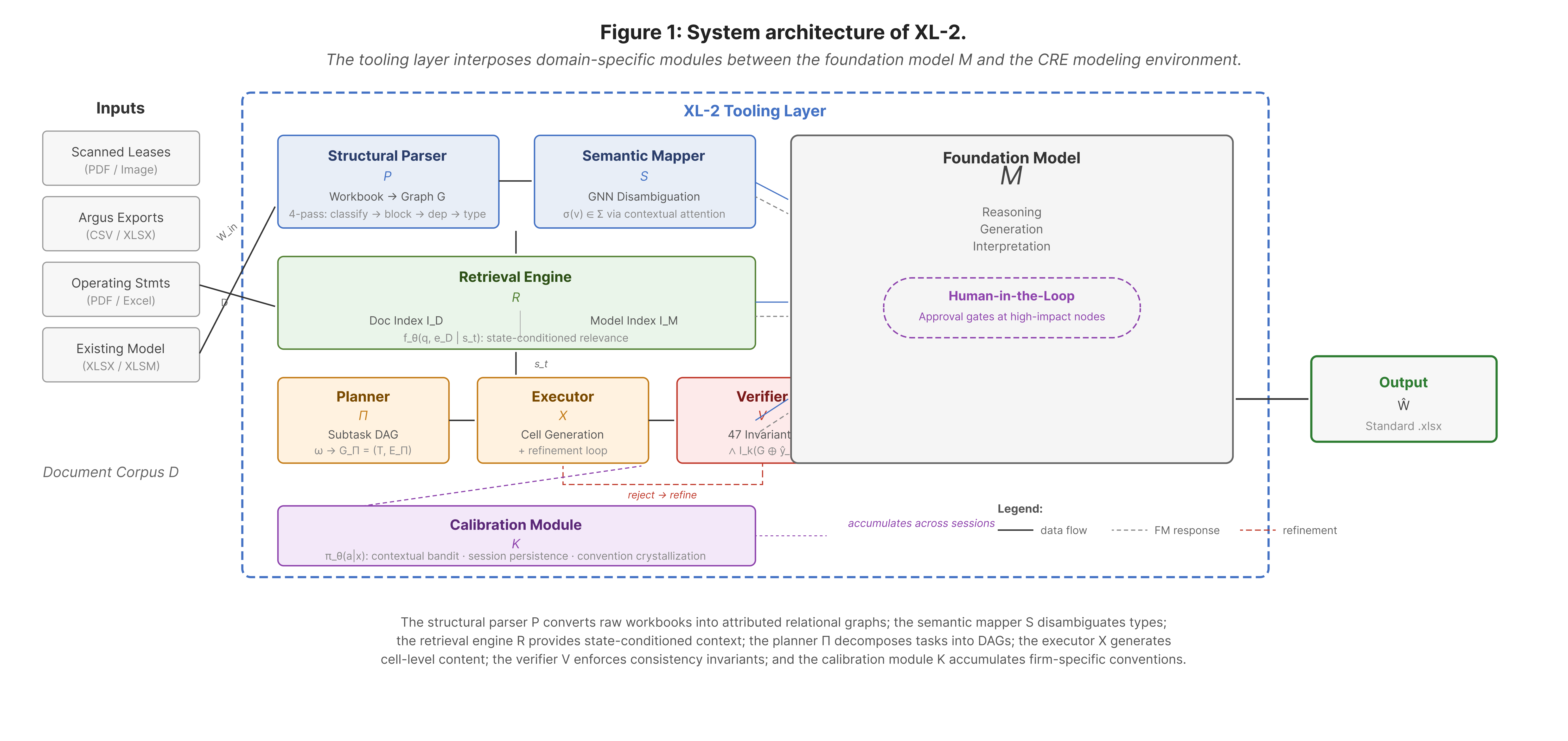
XL-2 addresses this by placing a purpose-built tooling layer between a foundation model and the spreadsheet environment. Rather than fine-tuning on CRE data or engineering more elaborate prompts, we constructed specialized modules that transform raw workbook structure into representations the foundation model can reason over accurately. The system has six core components and a persistent learning layer.
Understanding structure.
A structural parser reads raw workbooks and produces typed graph representations where cells become nodes and edges capture five kinds of relationships: formula references, named ranges, spatial layout, economic dependencies, and cross-tab connections. Each node receives a semantic type from a CRE-specific hierarchy. A cell labeled "Cap Rate" in an assumptions tab gets a different type than the same label in a valuation section. This distinction — invisible to models operating on raw cell grids — is what makes downstream reasoning reliable.
Resolving ambiguity.
CRE workbooks reuse labels extensively. "NOI" can refer to several distinct economic quantities depending on context. Our semantic mapper disambiguates by examining what surrounds a cell rather than what it says. When XL-2 processes two workbooks at once — a counterparty model alongside your internal template, for instance — it aligns equivalent entities across structurally different layouts automatically.
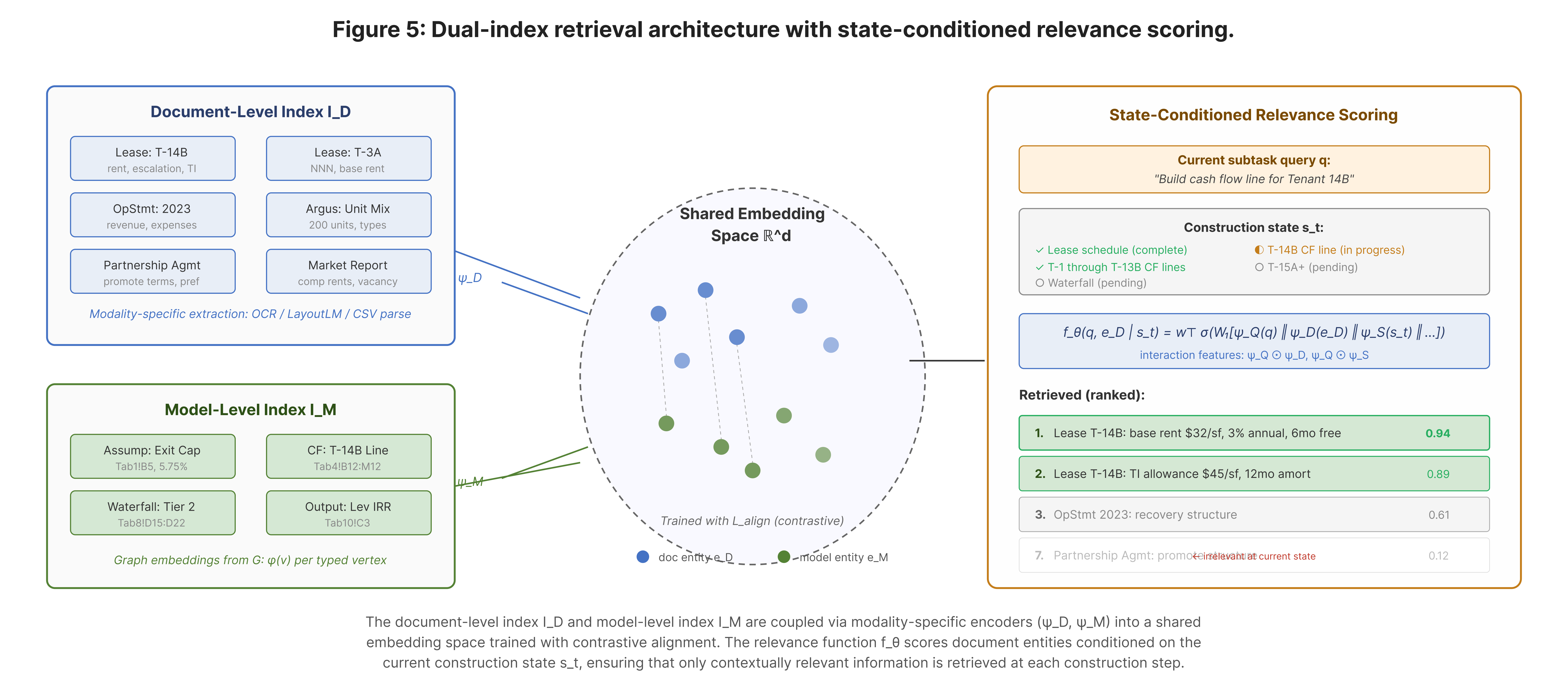
Retrieving deal data.
Real deal data is messy and heterogeneous: scanned lease PDFs, operating statements in Excel, Argus exports, market reports. XL-2's retrieval engine indexes entities from both the document corpus and the model being built in a shared space. Retrieval is conditioned on what the system is currently constructing. When building tenant 14B's cash flow, it surfaces 14B's lease terms. When structuring the partnership waterfall, it surfaces the JV agreement instead. The same document has different relevance at different stages of construction.
Planning construction.
A construction planner decomposes modeling objectives into task graphs with precedence constraints. Subtasks run in parallel where dependencies allow. Assumptions with heavy downstream impact on return metrics — the kind where getting it wrong cascades through the entire model — are gated for human approval before dependent work proceeds.
Building and verifying in parallel.
An execution engine processes tasks in topological order. For each task: assemble context, prompt the foundation model, generate cell contents, verify. Rather than building a complete model and auditing it afterward, XL-2 runs verification in parallel with generation. This is a deliberate architectural choice — errors in early tasks compound through every downstream calculation, so catching them at the point of generation prevents propagation.
The verification oracle enforces 47 consistency invariants across four categories: all formula references must resolve to valid cells, all formulas must reconcile on independent re-computation, return metrics at different levels of the model must be mutually derivable (levered equity IRR from partnership cash flow must match the IRR implied by unlevered returns adjusted for debt service and waterfall), and waterfall distributions must account for all distributable cash flow in every period. When verification rejects an output, structured diagnostics feed back to the model for retry. Persistent failure escalates to a human.
Learning firm conventions.
Different firms implement the same economics with different layouts, labeling patterns, and formula structures. A calibration module learns these conventions across sessions by collecting implicit feedback — whether a user accepts or modifies generated output. A classifier distinguishes one-time deal-specific overrides from standing preferences. Conventions that appear consistently (three or more occurrences at 80%+ consistency) get promoted to hard constraints on future generation. Over time, the system adapts to how your firm builds models, not just how models work in the abstract.
Why We Built It This Way
Tooling over fine-tuning.
Institutional financial models are proprietary. You will not assemble a fine-tuning dataset at scale. And fine-tuning conflates the foundation model's general reasoning ability with domain-specific grounding — two capabilities better served by separate, independently updatable systems.
Graphs over serialized text.
Flattening a 30-tab workbook into text for an LLM prompt discards exactly the structural information that makes the model interpretable: cross-tab dependencies, hierarchical layout, spatial relationships. The graph representation preserves all of it.
Contextual bandits over full RL for calibration.
Modeling decisions are approximately independent given context — knowing a firm's tab layout preferences does not change the reward distribution for assumption organization choices. The conditional independence structure makes bandits appropriate and avoids the sample complexity of full RL where user feedback is sparse.
What's Not Solved Yet
The system's type hierarchy is specific to commercial real estate. Extending to infrastructure, private credit, or fund-of-funds models requires new type systems, and doing so without losing disambiguation accuracy is an open problem.
The 47 verification invariants are manually specified. Novel deal structures may need new ones. Automated invariant discovery from corpora of well-formed models is a natural next step.
XL-2 currently operates on static document sets provided at session start. Real transactions involve evolving documents — new leases arrive, operating statements update, capital structure terms get renegotiated. Handling incremental document updates without full re-indexing, and propagating those changes through a partially built model, is architecturally straightforward but raises open questions we are actively working on.
The calibration module assumes decision-point independence, which does not fully hold when structural choices (like waterfall design) constrain downstream layout options.
What Comes Next
CRE financial models are one of the most complex structured artifacts in professional spreadsheet environments. We think the decomposition underlying XL-2 — separating structural grounding from reasoning, verifying in parallel with generation, learning conventions from use — generalizes beyond real estate to other domains where structured computation meets unstructured data.
The paper formalizes each component, provides complexity analysis, and details the training objectives. We are making it available today.